作者: 币安app官方 日期:2024-11-09 07:00
原文标题:当我们谈 Web3 数据,我们在谈些什么?|ZONFF Research
原文作者:Lewis Liao,高级投资经理
原文来源:Zonff Partners
当我们在谈 Web3 数据的时候,在谈些什么?想要弄清楚这个问题,首先我们要弄清楚,在 Web2 中数据是什么样的。本文将从数据的产生、收集、存储、管理和使用的全生命周期来展开讨论。在此之前,我们首先明晰数据是如何被定义的。
中国全国信息安全标准化技术委员会出台的《网络安全标准实践指南 - 数据分类分级指引》(征求意见稿 - v1.0 - 202109)中,将数据分类为个人信息、公共数据和法人数据。
其具体定义与实例如下表,
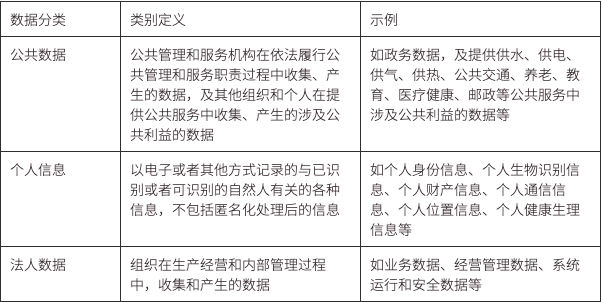
在每个类别之上,又根据数据泄露的危害对象和程度分为 5 个级别:公开级(1 级)、内部级(2 级)、敏感级(3 级)、重要级(4 级)和核心级(5 级)。对于公开级的数据,它更像是一个公共产品,是非竞争性和非排他性的。这种类型的数据一般由政府/公共组织提供,收益归其所有,如天气预报、宏观经济数据等等。
1.1 数据的产生、收集和存储
公共数据、个人数据和法人数据大部分是在我们日常使用计算机应用程序时产生的,其中与普通用户切身相关的是个人数据和法人数据。
那么个人数据和法人数据是如何产生和被收集的呢?一个高度抽象的互联网产品系统架构图如下所示,
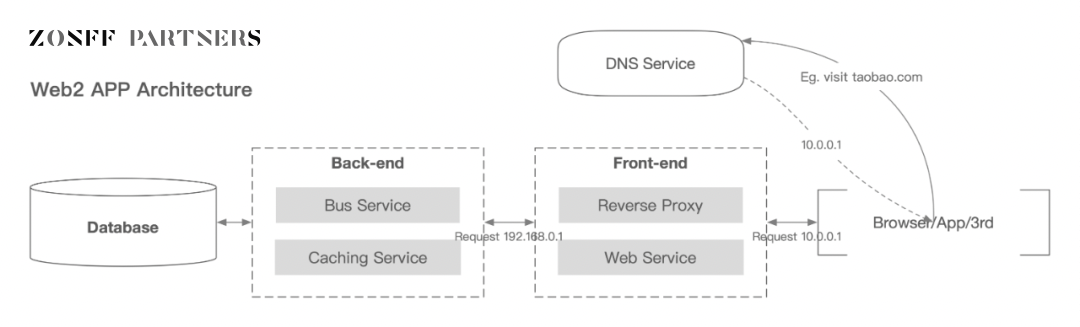
Web2 应用架构
图片来源:Zonff Partners
最底层的数据库存储着来自于后端传递过来的,用户与前端互动产生的数据。广义上说,这些都是用户数据。
就移动端应用来说,数据大概可以分为以下几类:
在这个分类当中,用户信息属于个人信息数据,日志和代码数据属于法人数据。其中值得讨论的是内容数据和行为数据,它们在 Web2 时代更多被中心化实体划分为自身的业务数据,即法人数据。
在 Web3 的应用中有什么不一样吗?Preethi Kasireddy 这张 Web3 产品架构可以帮助我们理解。
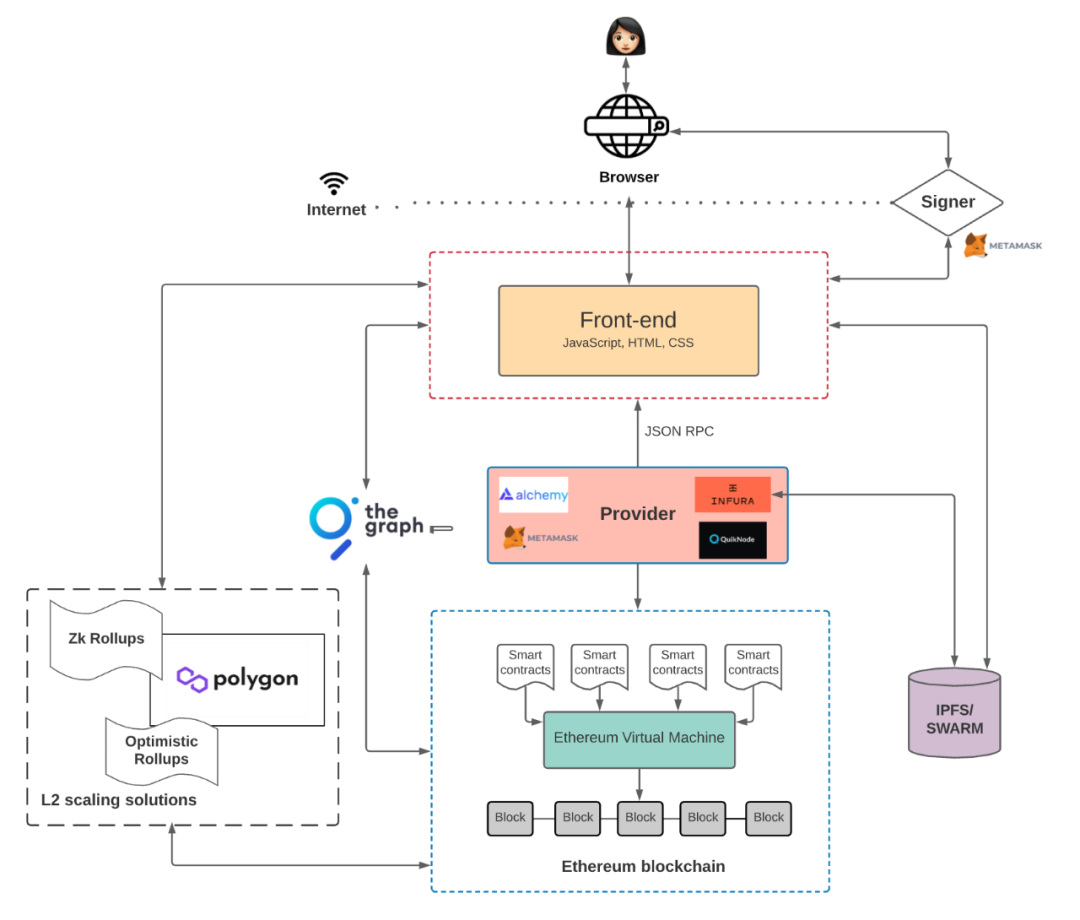
Web3 产品架构
图片来源:Preethi Kasireddy
与 Web2 应用相比,用户终端与前端是几乎没有什么变化的,不一样在于后端与数据库。用户通过前端与节点提供商互动(而不是某台中心化服务器),访问布置在以太坊等区块链上的合约代码(而不是服务器上的后端环境),并进行交互。在这个过程同样会产生上述几种类型的数据,由于技术架构的区别,Web3 产生的数据并不是由一台中心化服务器存储,对于不同方式产生的数据其存储的方式或有异同之处。
其中凡是智能合约交互产生的数据,都发布在区块链上,任何人可以都访问,它因此成为一种公共产品,这些包括资产信息、交易数据和合约代码。理论上,只要区块链块空间够大,任何数据都可以存储在区块链上,甚至也有的项目在尝试将区块链作为数据库来存储数据。

目前阶段,一个 Web3 应用产生的数据,除以上三类数据以外,大多数仍然采用中心化服务器的存储方式,这些包括前端代码、用户信息、内容数据、行为数据和日志数据。这是由于目前相关存储基础设施并不完善,项目方或受限于技术问题,或为了保证访问速度等原因采取了中心化方案。随着基础设施的不断发展,有很多功能越来越强大的存储基建的出现,如 IFPS、Stroj、Filecoin 和 Ceramic 等,也有越来越多应用已经开始将自身部署在去中心化存储上面,如将前端网站布置在 IPFS 上然后通过 ENS 访问,从而搭建一个去中心化网站前端以及将 NFT 项目对应的图片等文件数据用 Arweave 进行永存等等。
总的来说,在搭建一个 Web3 应用的时候,对于应用数据的存储,开发人员通常可以有 3 种选择:
目前,绝大多数 Web3 应用是通过第 2 种方式进行搭建的,也有一些特定应用,目前已经可以使用第 3 种方式进行搭建,极少数应用是通过第 1 种方式进行搭建的。那么,我们应该选择哪种方式存储呢?什么样的存储方式是趋势呢?
1.2 趋势:去中心化存储 - 数据和应用主权
当谈到搭建 Web3 应用的 3 种方式时,这有一个关键词:主权(sovereign)。这个词是当我们聊到 Web3 的特点时一个绕不开的话题,一般来说会包括数据主权和应用主权。那么主权重要吗?这是另一个话题,本文不作探讨,感兴趣可以阅读相关文章,如「Web3 数据市场展望」和「Web3 - Let the "right to data" awaken」。这里想从数据的角度,切入 Web3 主权确立的必经之路,并推演基础设施发展的方向和重点。
关于数据主权,包括数字资产主权和用户数据主权,「 纵向流动性:价值如何互联互通」一文中有谈到关于代币可以定义用户的数字资产主权(身份、关系与物权),这是由一个难以篡改的广泛共识所决定的。最基础的,这些权利的定义由区块链本身就能完成,如一个代币归属于哪一个地址。可一旦涉及到更复杂的数字产品权利归属,就会有很多问题出现,比较典型的就是 NFT 对应的图片(或文章等)的存储问题,「NFT:数字所有权的革命」中对这个问题进行过讨论。大多数 NFT 的现状是其对应的数字产品存储在某个地方的中心化服务器上,一旦服务器崩溃或者被黑,那么用户所拥有的就只是一串链上哈希,哈希背后真正的 “物品” 则随时可以被偷窃或者替换,变得毫无价值。
此外,用户数据主权作为 Web2 与 Web3 最为明显的分界线之一,是为 Web3 创新与进步所呐喊的旗帜。就此,Ceramic 设想了一个数据宇宙,一个可组合的、网络级规模的数据生态系统,由每个人拥有,但不被任何人独有。用户数据跟随用户从一个应用到另一个应用,用户作为中心控制自己的数字宇宙。目前,几乎还没有应用可以实现这一点,Cyberconnect 作出了很好的尝试,它创造了一个去中心化社交图谱协议,希望在应用间实现用户社交关系数据的可互操作性。但目前来讲,该应用并没有保证用户的数据主权,尽管他们已经开始转移到 Ceramic 之上进行建设,但一切仍然还在路上。
关于应用主权,有人把主权应用称为 “超级结构”,它拥有不可停止、免费、有价值、可扩展、无许可、正外部性和可信中立等特征,这些综合起来提供了一个数字世界的公共产品,打造了 “元宇宙”(如果你信的话)的基础设施。目前绝大多数所谓 Web3 的应用其应用主权程度都不高,它们不是真正的公共产品,它们可以很容易被强权制裁与改变,Tornado Cash 事件非常直接地说明了这个问题。主要原因之一是因为虽然这些应用协议层的合约代码都发布在区块链上,但如前端、域名等组件仍然由第三方中心化的实体所控制。
为了实现数据主权和应用主权,Web3 应用的构建方式至关重要,其基础出发点就是存储,数据存在哪里,怎么存才能保证用户能够拥有主权?总的来说,根据用户的数据类型不同,可以有不同的解决方案:
目前,大多数 Web3 应用采用「将智能合约逻辑存在区块链上,其他存在传统后端上」的原因是目前没有足够好用的去中心化基础设施可以替代原本的中心化基础设施方案。
首先,IPFS、Filecoin 与 Arweave 等去中心化存储都是静态存储,这使得其缺乏计算和状态管理能力,无法实现更高级的类似数据库的功能(如可变性、版本控制、访问控制和可编程逻辑),而虽然 Ceramic 是动态存储,一定程度解决了这些问题,但 Ceramic 目前的访问速度仍然较为缓慢,且开发套件不够完善,并且其去中心化程度也一直为人诟病。
IPFS、Filecoin 与 Arweave 等去中心化存储的主要作用是静态存储了如图片、文档和静态代码等文件非结构化数据,因为其难以被篡改的特性一定程度上的保障了如 NFT 之类的数字主权,链上哈希代码与链下去中心化存储地址之间的联系一旦建立,就很难被外力以非常的手段影响。而前端代码搭建在上面也促进了应用主权的完整性,但由于目前阶段的存储技术仅仅是存储而已,计算能力的缺乏导致其功能支持远远落后于中心化的服务器方案。
目前市面上的主流去中心化存储情况如下表所示,本表格参考「Web3 去中心化存储进化史」总结更新,
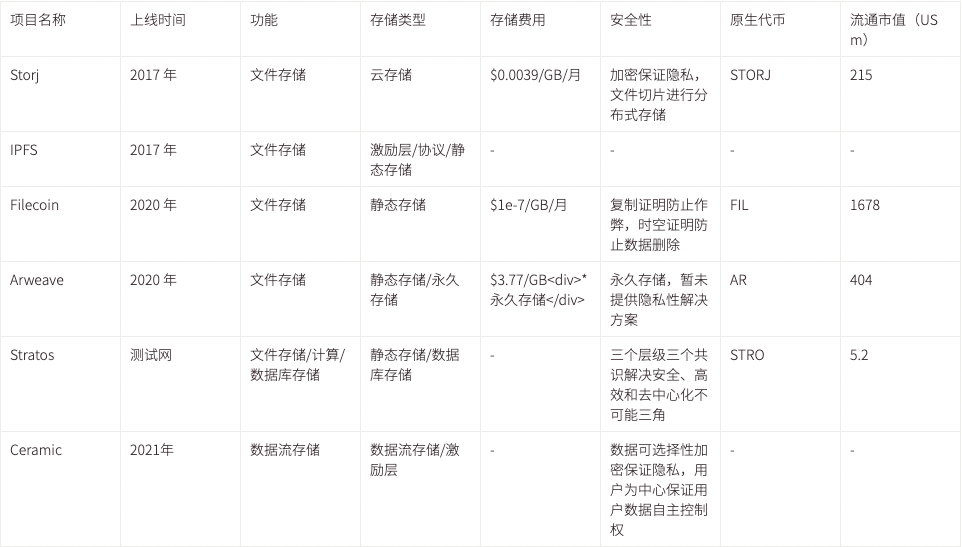
数据来源:CoinmarketCap
时间:2022 年 8 月 23 日
目前来说,大多数的存储方案只是实现了一个「去中心化硬盘」,这满足了最基本的需求,更高级一些的如基于存储的计算需求并未完全满足,这些计算包括本地开发环境渲染、数据流的插入与提取等等,这些都是目前 Web2 应用最常用和最必要的功能模块。Ceramic 基于数据流存储的创新使得数据的权限管理、版本控制、动态存储和可组合性得以实现, Stratos 则正在尝试提供一个更完善的、全套的解决方案,包括数据库存储、静态存储、计算和共识等多个模块。此外,Arweave 和 Filecoin 也意识到了计算的重要性,正在自己或者鼓励生态建设相关模块,如 Filecoin 已经推出了 FVM 以支持在 Filecoin 上的计算 。
2.1 数据的管理
将 Web3 应用建立在去中心化存储之上,使得他们更加不容易被外力干扰,打破了垄断与强权。但仅仅是存储还不够,还需要存储环境的渲染计算、数据处理、权限配置和隐私保护等等技术的支持,才能够保证应用的主权、用户的数据主权,从而实现数字世界个人主权的崛起。尤其是权限控制和隐私保护问题,它们应该用一个高级别的主权技术方案实现。Web2 应用中这些级别数据都是按照不同的安全防护级别,保存在某些具体的中心化服务器上,其安全性由网络安全保障,其主权性由平台保障(如企业平台、政府平台等等)。这种数据管理模式下,用户服从于超级管理员,对于数据本身,用户没有任何权利。此外,数据安全也受制于超级管理员这一中心化实体,如前段时间某地区的公安数据泄露事件,一个超级管理员将其私钥泄露,使得上亿人的个人私密信息泄露。
Web3 的数据管理应当具有以下两大特性:
如何对 Web3 数据进行管理,取决于该数据是如何存储的。
IPFS 和 Filecoin 以内容为中心,通过 Content ID(CID)来访问存储的内容,在此基础之上通过搭建第三方应用进行数据管理,如通过 ChainSafe Files,可以本地化方式解决单点登录问题后,可以方便地通过非对称加密对数据进行加密存储。以内容为中心的管理模式,使得用户管理变得困难,如何给数据定所有权变得较为复杂。Filecoin 除了提供存储之外,它的生态的拓展性会比其他的底层来说要高得多。特别是接下来 FVM 推出之后,可能会有一些针对数据存储数据检索方面的一些垂直领域推出特色的工具,能帮助用户帮助企业更好地去管理它的一些数据,保证数据的安全,然后开发很多的一些新的应用。
Ceramic 也是基于 IPFS,但以用户为中心,基于 IDX Protocol,3ID DID 方法(CIP - 79)构建了 Ceramic-native 的账户体系,可用于对 Ceramic 进行身份验证,用户可以使用区块链钱包控制 3ID DID 在数据流上执行交易并管理自己的数据。这是通过将 DID 与数据关联后存储进数据模型实现的,数据模型定义了用户数据的格式(schema),只要使用同一个数据模型的应用都共享该数据格式。
Arweave 是一个一次付费、永久存储的链上数据去中心化存储项目,数据公开透明地存储在链上,任何人都可以访问,通过 Arweave 区块链浏览器可以浏览存在链上的数据。这种模式下的数据管理与管理链上数据一模一样,没有访问权限控制,以及对原来数据的 “热更新”,每次更新数据,其索引地址都会发生变化,这一点 IPFS 和 Filecoin 不存在问题,但其好处是数据归属于哪一位用户非常明确,有利于对于数据权益进行回溯。
Stratos 也是基于区块链共识的存储,会专门维护一个索引树,记录数据存储的路径,从而保持对数据更新的追踪。与 Arweave 不同的是,Stratos 每一个存储节点(Resource Node)被设计成同时拥有计算能力、存储和内容访问控制服务,项目方自己会搭建基于区块链本身的数据库用于数据的动态吞吐,其形态和管理模式接近于去中心化云计算机。
2.2 趋势:去中心化数据市场
在用户拥有数据所有权的情况下,数据市场是一个必然趋势,数据作为资本要素在其中流通。在 Filecoin 上就曾经有过数据市场的尝试,Fivehive 由去中心化应用开发工作室 OB1 搭建并维护,是一个开源市场,支持数据集的上传、维护、购买和(或)转让。该项目 Github 已经在两年前就停止了更新和维护,大概率是失败了。
Ceramic 的数据模型市场
Ceramic 在其数据宇宙中提到了他们要打造的开放数据模型市场,因为数据需要互操作性,它能够极大地促进生产力的提升。这样的数据模式市场是通过对数据模型的紧急共识实现的,就类似于以太坊中的 ETC 合约标准,开发人员可以从中选择作为功能模板,从而拥有一个符合该数据模型的所有数据的应用程序。目前来说,这样的市场并不是一个交易市场。
关于数据模型,一个简单的例子是,在去中心化社交网络当中,数据模型可以简化为 4 个参数,分别是:
那么数据模型如何在 Ceramic 上进行创建、共享和重用,从而实现跨应用程序数据互操作性呢?
Ceramic 提供了一个数据模型注册表(DataModels Registry),这是一个开源的、社区共建的、用于 Ceramic 的可重用应用程序数据模型的存储库。在这里,开发人员可以在其中公开注册、发现和重用现有数据模型 - 这是构建在共享数据模型上的客户操作应用程序的基础。目前,它基于 Github 存储,未来它将分散在 Ceramic 上。
添加到注册表的所有数据模型都会自动发布到 @datamodels 的 npm 插件包下面。任何开发人员都可以使用 @datamodels/model-name 安装一个或多个数据模型,使这些模型可用于在运行时使用任何 IDX 客户端存储或检索数据,包括 DID DataStore 或 Self.ID。
此外,Ceramic 还基于 Github 搭建了一个 DataModels 论坛,数据模型注册表中的每个模型在该论坛上都有自己的讨论线程,社区可以通过它来评论和讨论。同时,这里还可以供开发人员发布关于数据模型的想法,从而在将其添加到注册表之前征求社区的意见。目前一切都在早期阶段,注册表中的数据模型并不多,收纳进入注册表中的数据模型应当通过社区的评定成为 CIP 标准,就像以太坊的智能合约标准一样,这为数据提供了可组合性。
Ocean 的数据交易市场
Ocean Protocol 以数据交易市场为核心,建立了一个去中心化的数据服务供应链网络。下图显示了创建数据服务供应链所需的主要服务,提供数据、算法、计算、存储、分析和策划。这些组件与服务执行协议(如服务等级协议)、安全计算、访问控制和许可绑定在一起。
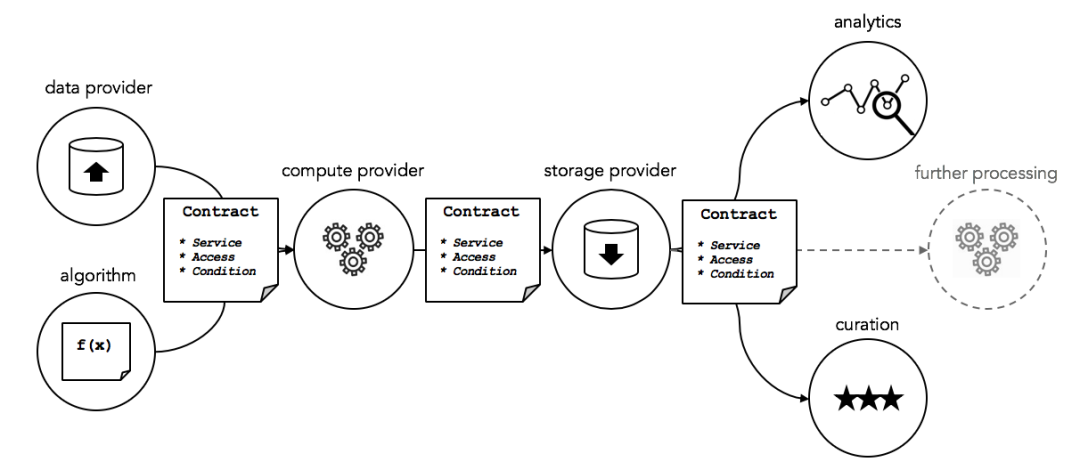
图片来源:Ocean Protocol
主要的参与角色为数据使用者、服务提供者、市场、服务发布者、验证者和策展人。Ocean 提供了全套数据科学工具,数据使用者可以在 Ocean 上建立数据服务管道以自动化运行数据算法从而对数据进行加工处理以及价值发现。在这个过程中,数据使用者无法下载全部数据集以及看到全部数据集,因此保护了数据集不被盗取,使用者购买的是数据集的使用权,而非拥有该数据集。
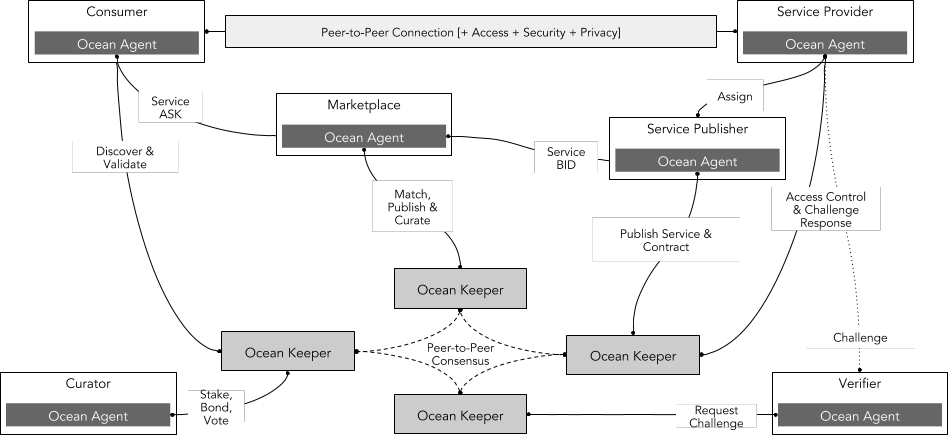
来源:Ocean Protocol
除此之外,Ocean 还和其他机构合作建立数据市场,如它与梅赛德斯-奔驰的去中心化数据市场 [Acentrik] (https://acentrik.io/) 在其最近推出的 Enterprise Release 中联手。Acentrik Marketplace 由 OceanONDA V4 智能合约和库驱动,可以发布数据服务、部署和铸造数据代币和 Acentrik 资产管理代币,并通过花费来消费数据服务。
3.1 数据的使用与堆栈
基于以上内容的理解,我们提出了 Web3 数据堆栈,见下图,

Web3 数据堆栈
图片来源:Zonff Partners
目前行业内关于 Web3 的数据使用,绝大多数是链上数据,层出不穷的数据分析工具与索引工具出现,链上数据这个巨大的金矿已经被充分地挖掘,上图的数据表和分析应用分类中绝大多数都是链上数据的挖掘,只有少部分涉及到链下数据。总的来说,数据的使用链路是一个 ETLA(Extract、Transform、Load、Analysis)的过程,每个节点上都具有代表性的项目。提取(Extract)项目的代表是 The Graph,而转换(Transform)成可用数据表和加载(Load)环节的项目代表是 Dune 和 Luabsae,分析(Analysis)的代表是 Nansen 和 NFTGO。
而在去中心化存储上 ETLA 整个流程的支持项目几乎还是荒漠,只有一些提取类项目,这里存在巨大的机遇和挑战。The Graph 和 Ceramic 社区本身正致力于提取 Ceramic 上的数据,Orbis 的创始人也尝试做了一个 Cerscan 用于浏览 Ceramic 上的数据。Arweave 已经可以通过 The Graph 用子图读取和管理 Arweave 存储的数据,Filecoin 上也有相关第三方项目在做这件事情。但 TLA 的过程目前还无人问津,其中最大的原因是存储在不同去中心化存储上的数据异质性很高,很难有一个统一的模式去挖掘这些数据的价值,其中最有希望踏出这一步的是 Ceramic,这是因为其数据模型的存在使得 Ceramic 上数据的异质性指数级降低,从而使得数据的可利用性变得更高。
除了链上数据以外,还有很多项目在尝试将链上数据与链下数据进行打通,这类项目可以看作为 “链改” 型项目。
类型分类有:
Web3 数据的使用范式和 Web2 存在明显的不同,其主要在于数据聚集在一起的方式,即不同类型的数据其存储、索引、提取、整合和利用的方式都会存在差别。根据前文的分类,这里做一些简单的总结:
公开数据:包括《网络安全标准实践指南 - 数据分类分级指引》分类中的公共数据和部分法人数据。作为公共产品,是可以被公开挖掘价值的数据,接入无需许可,但可以追溯用户所有权,从而追溯空投分润,典型的例子是链上数据和存储在去中心化存储上的非加密应用数据(如用户帖子、点赞和评论等)。其使用最重要的上游支持是索引应用,如 The Graph,或 Web3 原生数据库的应用,如 Tableland。
私密数据:包括《网络安全标准实践指南 - 数据分类分级指引》分类中的个人信息和部分法人数据。作为需要加密存储,且需要一定隐私权限配置的数据类型,其接入有许可,不可被公开获取,若存储在去中心化存储和区块链上,则需要可权限配置的加密存储。或通过其他手段,如 ZK、MPC 和 TEE 等隐私技术手段保护。其使用最重要的上游支持是数据库应用,如 Kwil 和 Ceramic 等。